今回はスマホの連写写真の合成から背景をぼかした、いわゆるポートレート風画像を作ってみようと思います。あまり長秒露光関係なくなってきました。だんだんネタがなくなってきましたが、もう少し頑張ってみます。

Pythonでの画像処理遊びです。スマホの連写写真から何が作れるかなぁ。の続きです。今回は背景をぼかす際に、被写体と背景の境界部分が背景のぼかしに影響しないよう工夫しました。プーさんの背景ぼけてるのわかるかなぁ…。
背景ぼかし
カメラで絞りを開いた時に撮影できる被写界深度の浅い、背景がぼけている写真。いわゆる一眼レフって感じの写真で、F値の小さい高っかいレンズが必要なあれです。撮影したい被写体だけにピントが合って、周りのうるさい背景がきれいにぼけてたりすると、主題となる被写体が際立っていい感じになります。
もちろんでかいセンサのカメラと、高いレンズで撮るのが一番なのですが、これを模した画像処理もいろいろあります。ただ処理もピンキリで、被写体を切り出して、それ以外をぼかすってだけのイマイチなモノから、深度センサまで使ってもっともらしいのを作るものまで、いろいろです。一長一短あり、正直これらの処理と勝負する気にはなれないです。
今回もいわゆる連写写真から位置合わせをして、その位置があった場所、合わなかった場所それぞれに対して違うパラメータで処理をして、背景だけをそれっぽくぼかした写真合成をしてみようと思います。
画像処理の概要
前回試した、流し撮り風合成をベースにします。基本的な着想は同じです。

この記事では、複数画像の間で、被写体の位置合わせが決まった位置では流さず、それ以外の場所では流し(ぼかし)をかける。というものでした。この位置合わせが決まったか否かの尺度として、フレーム間の差分を使いました。
今回も基本的にはこの流れです。位置合わせが決まった所ではぼかさず、それ以外(背景)に対してはぼかし処理を入れます。
スマホでの撮影方法
基本的にはこれまでと同様にスマホのオート設定で連写。この撮影スタイルはぶらしません。ただ、被写体と背景を分離するために、その複数枚の写真には視差を持たせる必要があります。そのためわざとカメラを手振れさせます。とはいえ室内のような暗いところだとシャッタースピードが延びてしまうので、被写体もぶれます。視差が出る程度にずらして静止、ずらして静止、といった撮影方法を取る必要があります。
iPhoneSEをのオート設定+連写で撮っています。
視差とは?
人が左目と右目の見え方の違いでその物体への距離を感じることができます。左目で見た画像と、右目で見た画像には違いがあり、そこから奥行き感を感じています。いわゆるステレオ視とかそんな言い方でコンピュータビジョンの世界では言われていますが、今回は距離とかそんなものを測定したいわけではないので、そんな細かいことは気にしません。左目と右目で見え方に違いがあることにヒントを得ています。

こんな感じで左目画像と右目画像では差があります。プーさんに対して背景の相対位置がずれています。つまり左目画像と右目画像の2枚に対して、ピントを合わせたい被写体(この場合プーさん)の位置を合わせると、背景の位置は合わない。ということになります。この原理を使います。
画像処理の詳細
まず、被写体の位置(座標)を特定して、位置合わせをします。前の記事で説明したものと同じです。その後その2枚の画像の差分を取ります。その差分に応じてぼかしをかけていきます。
位置合わせ
以前とやっていることは同じです。追跡位置を指定します。通常被写体でピントを合わせたい箇所です。人物なら通常目をそのターゲットにします。この座標と範囲はPhotoshop等で拾っておきます。

プーさんの顔をトラッキングしました。この矩形の左上のx,y座標と、この矩形のサイズwidth,heightを覚えておきます。
特徴点検出
これも同じ。この領域の特徴量を取ります。これまでの処理だとこの画像のすべての領域を対象に特徴点探索していましたが、今回の場合は追いかけたい対象に絞って特徴点を取ります。
これを想定した引数が用意されています。maskです。maskとは必要な箇所だけ値を持った1chの画像の事です。今回の場合は、電車の先頭車両の位置をマスクとして指定してあげると、そこだけの特徴点を取ってくれます。これを特徴点算出の際の関数detectAndComputeに渡してあげればよいです。コードとしては
###############################
# AKAZEによるマッチングポイントの探索
def get_matcher_base(img, x, y, width, height):
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
mask = cv2.rectangle(np.zeros_like(gray), (x, y), (x+width, y+height), color=1, thickness=-1)
sift = cv2.AKAZE_create()
# find the keypoints and descriptors with AKAZE
kp2, des2 = sift.detectAndCompute(gray, mask=mask)
return kp2, des2
こんな感じ。今回は矩形マスクですが、任意の形のマスクが渡せます。そのマスクを使って画像に対してAKAZEの特徴点を見つけます。
位置合わせ、合成
以前とやっていることは同じです。ベースとなる画像以外の画像は全体に対して特徴点を探し、その特徴点同士のマッチングを取って、一致するもの同士を見つけ、そこへのAffine行列を求めるものです。
差分に応じてエッジ保存したぼかし
今回の処理の特徴です。逆にここ以外はこれまでの処理の流用です。
全体をぼかして、被写体部分はぼかしていないオリジナルのものを使う。というのが単純な方法なのですが、これだと被写体のエッジ部の画素が背景部に漏れてしまいます。課題です。
ぼかしの基本的な処理ですが、注目画素の周囲の小面積の画素平均を取ることで画像がぼけます。この小面積の平均を取る際に、その小面積の中に対象とする被写体のエッジ部を含んでしまうことでこの現象が起きてしまいます。例えば、
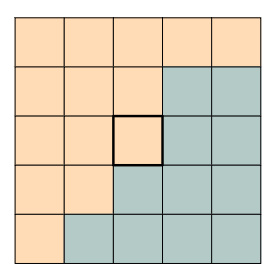
注目画素が中心の画素で、小面積が5×5画素の上記エリアだとして、オレンジが背景、青が被写体だとします。この注目画素は背景なのでぼかしたいです。そのためこの5×5のエリアの平均を取ると、どうしても青の成分を含んでしまいます。逆にぼかしたくない被写体部の青に関しては、そもそも平均化しないので、オレンジの成分を含むことはないです。背景部なのでこの青の成分は不要です。この青の染み出しを抑える方法を考えます。
差分取得
位置合わせが済んだ2枚の画像の差分を取ります。この差分の大小で位置合わせができているか否かを判断します。位置合わせができていればそれは被写体で、できていなければ背景。被写体であれば差分は小さく、背景であれば差分は大きくなります。処理は単純な引き算で行います。RGBそれぞれで差分を取ると変な色が出るので、今回はGreenだけ使いました。
img1 = base[:,:,1]/255
img2 = current[:,:,1]/255
diff = np.clip(np.abs(img1 - img2)*5, 0, 1)
diff = np.stack([diff, diff, diff], 2)
画像を1に正規化しています。この処理で得られるdiffは0~1の範囲の浮動小数点です。差分を5倍しているのは2割の差分があれば十分違うだろうという経験的なパラメータです。適当です。Greenで取った差分をRGBに展開するためにnp.stackを使っています。理想的イメージは
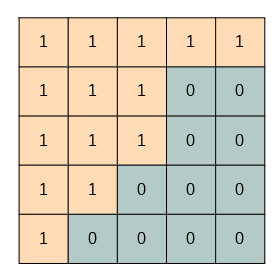
こんな感じ。理想的な位置合わせができていれば、オレンジの背景部は1に、被写体部は0になるはずです。
平均化カーネル作成
小面積平均を取るためのフィルタカーネルを作っています。何のことはない全1のsize x sizeの矩形フィルタです。カーネルの合計を1で正規化します。
kernel = np.ones((size, size), np.float64)
kernel = kernel/np.sum(kernel)
画像マスク
続いて画像を差分画像でマスクします。こうすることで、1が立っている箇所すなわち差分が大きい背景画像だけの画像を作ることができます。
blur = diff*img1
blur = cv2.filter2D(blur, -1, kernel)
こんなイメージ
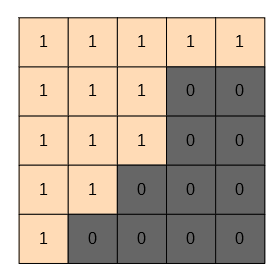
被写体部がすべてゼロに落ちるはずです。そしてそれを平均化しています。この例では5×5画素の平均とします。これにより平均化を取る対象に被写体が含まれません。(青が染み出してきません)
被写体部加算
ただこれだとゼロに落ちている部分を平均対象にしてしまっているので、全体暗くなります。このゼロに落ちている部分を補います。補う画素は自分自身(注目画素)を用います。この補う量ですが、ゼロに落ちている画素の分だけ補う必要があるので、このゼロの数を数える必要があります。
diff_sum = cv2.filter2D(1-diff, -1, kernel)
このように、差分画像のゼロイチを反転させて、加算することで0の合計を出します。
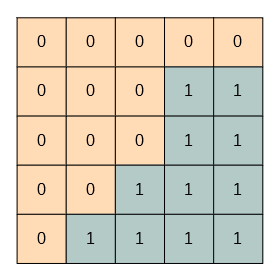
これを平均すると、25画素中の11画素が0だったことがわかります。値としては11/25が得られます。これで画像をマスクして、先ほど求めたぼかし画像を加算します。
blur = blur + (diff_sum * img1)
マスクはこんなイメージ。厳密には25で割った値です。
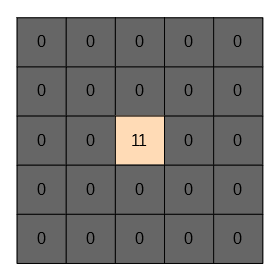
これでオレンジの箇所を平均して、残りの成分を注目画素で加算したそれっぽいボケ画像を作ることができます。
コードとしてはトリッキーに見えますが、やっていることはシンプルです。これで差分が大きいところはぼけ、小さいところはぼけない。そんな画像が作れます。今回説明を簡単にするために0or1の差分画像で説明しましたが、コード上はその途中の値も含んでいますが原理は同じです。
結果
2枚の画像から作りました。

微妙な違いわかりますかね…。ちなみに差分は

一応背景に集中してます。(白いところが差分大の箇所)

これくらいの差です。一応プーさんはぼけず、背景だけぼけています。今回の撮影だと視差を大きく取り過ぎたので、プーさんそのものも複数の写真の間で形が崩れ、エッジも微妙にずれてボケてしまいました。鼻先だけビタっと位置合わせできています。被写体との距離にもよりますが、視差はそんなに意識しないでもよかったかもしれません。
まとめ
差分に応じてぼかしを入れる処理を考えてみました。処理そのものはうまく動いています。があまりに微妙な違いです。テスト用に作った画像からだとうまく行っていたので、いいかなぁと思って実写真で試したのですが、意外と撮影にコツがいりそうです。いや、何も考えず連写して自然の手振れで取ればよかったのかなぁ…。
実はこのぼかし処理、カメラを固定した撮影にも使えそうです。その差分から移動体をぼかすことができるはずです。差分の概念を逆にすれば背景をぼかすこともできます。それなりに応用もできそうです。
今後ちゃんと写真を取り直します。スマホ連写シリーズもそろそろネタが尽きてきました。
コード
全コードです。ファイル指定するための簡易UI付きです。コピペで動くと思います。
今回の結果は2枚の画像合成で作りましたが、このコードではN枚で処理できるようになっています。
# -*- coding: utf-8 -*-
##
# @file bulb.py
# @date 2020/4/8
# @brief 背景ぼかし合成プログラム
import cv2
from PIL import Image
import glob
import numpy as np
import tkinter as tk
import tkinter.filedialog
import threading
dirName = ""
dstName = ""
nowprocess = False
##
# @brief 差分に応じたぼかし
# @param base 入力画像(numpy array)
# @param current 入力画像(numpy array)
# @param size カーネルサイズ(大きいほどぼける)
# @return 結果画像
def blur_from_diff(base, current, size):
img1 = base[:,:,1]/255
img2 = current[:,:,1]/255
diff = np.clip(np.abs(img1 - img2)*5, 0, 1)
diff = np.stack([diff, diff, diff], 2)
img1 = base/255
kernel = np.ones((size, size), np.float64)
kernel = kernel/np.sum(kernel)
blur = diff*img1
blur = cv2.filter2D(blur, -1, kernel)
diff_sum = cv2.filter2D(1-diff, -1, kernel)
blur = blur + (diff_sum * img1)
return blur*255
###############################
# img1とimg2から、img2にマッチするようなimg1の変換行列を求める
def get_affine_matrix(img1, kp2, des2):
kp1, des1 = get_matcher(img1)
if len(kp1) == 0 or len(kp2) == 0:
return None
# Brute-Force Matcher生成
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
# store all the good matches as per Lowe's ratio test.
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
if len(good) == 0:
return None
target_position = []
base_position = []
# x,y座標の取得
for g in good:
target_position.append([kp1[g.queryIdx].pt[0], kp1[g.queryIdx].pt[1]])
base_position.append([kp2[g.trainIdx].pt[0], kp2[g.trainIdx].pt[1]])
apt1 = np.array(target_position)
apt2 = np.array(base_position)
# 行列の推定
return cv2.estimateAffinePartial2D(apt1, apt2)[0]
###############################
# AKAZEによるマッチングポイントの探索
def get_matcher(img):
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
sift = cv2.AKAZE_create()
# find the keypoints and descriptors with AKAZE
kp2, des2 = sift.detectAndCompute(gray, None)
return kp2, des2
###############################
# AKAZEによるマッチングポイントの探索 マスク付き
def get_matcher_base(img, x, y, width, height):
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
mask = cv2.rectangle(np.zeros_like(gray), (x, y), (x+width, y+height), color=1, thickness=-1)
sift = cv2.AKAZE_create()
# find the keypoints and descriptors with AKAZE
kp2, des2 = sift.detectAndCompute(gray, mask=mask)
return kp2, des2
###############################
# 処理開始(スレッドで動く想定)
def process():
global dirName
global nowprocess
global dstName
flist = glob.glob(dirName + "\\*.jpg") # ソースの写真群がある場所
nowprocess = True
fname = flist.pop()
print("base file:", fname)
image = Image.open(fname)
exif = image.info["exif"] # exif情報取得
base = np.array(image, dtype=np.uint8)
height, width = base.shape[:2]
sums = np.zeros(base.shape, np.float64)
cnt = 0
kp2, des2 = get_matcher_base(base, 1748, 1072, 940, 1136)
for fname in flist:
print(fname)
current = np.array(Image.open(fname), dtype=np.uint8)
mtx = get_affine_matrix(current, kp2, des2)
if mtx is not None:
current = cv2.warpAffine(current, mtx, (width, height))
sums += blur_from_diff(base, current, 21)
cnt += 1
out = (sums/cnt).astype(np.uint8) #(sums / cnt) # 平均化
Image.fromarray(out).save(dstName, "JPEG", exif=exif, quality=95)
button2["text"] = "実行"
nowprocess = False
####################################
## フォルダ選択ボタン
def button1_clicked():
if nowprocess:
return
global dirName
dirName = tk.filedialog.askdirectory()
####################################
## 実行ボタン
def button2_clicked():
if nowprocess:
return
global dstName
dstName = tk.filedialog.asksaveasfilename(filetypes=[("JPEG file", ".jpg")])
if dstName != "":
button2["text"] = "実行中..."
thread = threading.Thread(target=process)
thread.start()
####################################
## main
if __name__ == '__main__':
root = tk.Tk()
root.geometry('200x100')
button1 = tk.Button(text="選択", command=button1_clicked, width=20)
button1.place(x=30, y=20)
button2 = tk.Button(text="実行", command=button2_clicked, width=20)
button2.place(x=30, y=60)
root.mainloop()


コメント