画像から直線を検出するために用いられるHough(ハフ)変換ですが、同じような考え方で円も見つけることができます。どのような原理で見つかるのか考えてみます。
以前直線を見つけてみました。
これの続きです。ハフ変換による直線検出に関して、まずこちらを眺めていただいてからの方がいいかもしれません。
ハフ変換
ハフ変換は、デジタル画像処理で用いられる直線の検出を行うための変換になります。直線だけでなく、円や任意の形態の検出にも使えるらしい。が今回は円を検出するための処理に関して解説をしようと思います。
とある座標上1点を通る円は無限に存在します。そりゃそうですよね、点に接する円を考えれば無限に存在しえます。
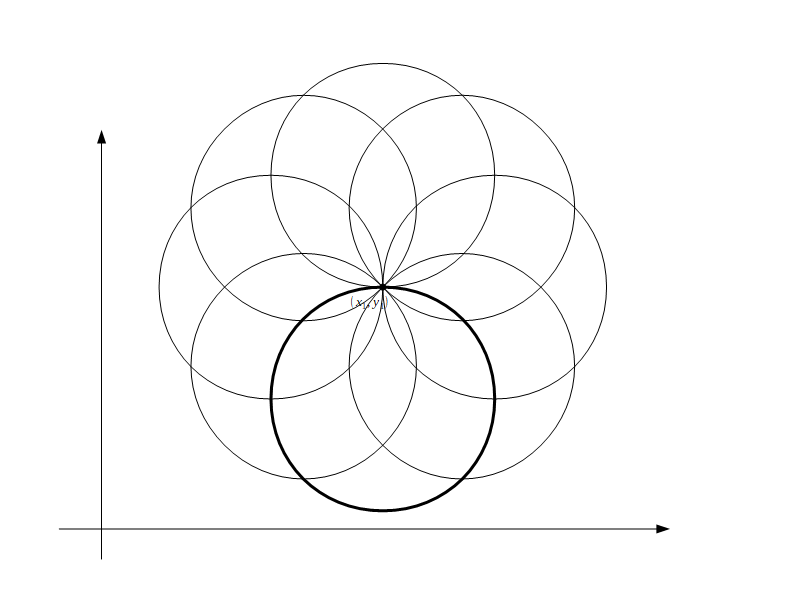
一つ一つの円に一意の中心座標と半径を持つ\(r^2 = (x-a)^2 + (y-b)^2\)の式が与えられます。無限だとわかりにくいので例えば図のように8つとしてみます。
別の点を考えます。
同じように8つの円が書けますが、2つの円が重なる円は1つだけ(厳密には2つ…。)になります。その(r,a,b)がこの2点を通る円を表す式になります。他の7つの円は共通の(a,b,r)が現れません。
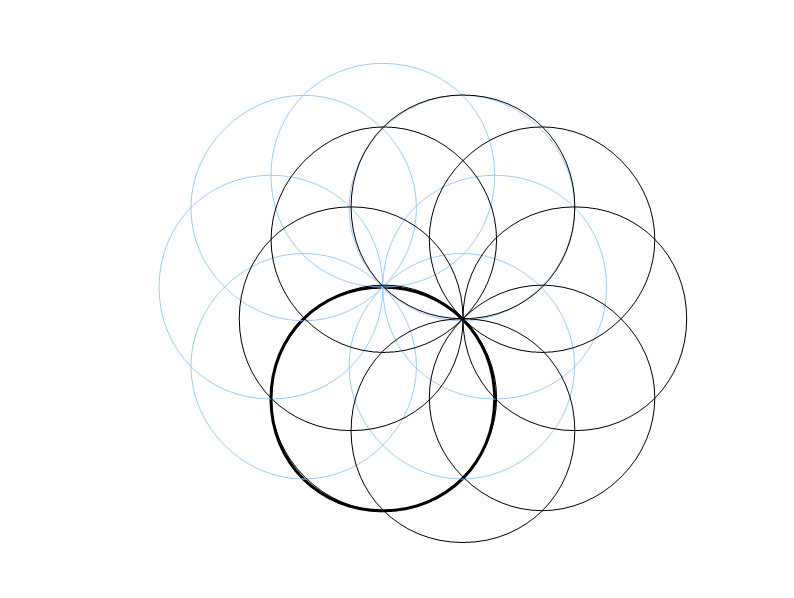
薄い青が前求めた円、太い円が2回の描画で重なった円(実はもう一つ重なってますが…)。円の候補となる点群すべてに対して(a,b,r)を求めると、共通して通る(a,b,r)がその点群の数だけ求まります。10個の点で計算すると同じ(a,b,r)が10回現れ、逆にそれ以外の(a,b,r)は1度きりしか現れません。
3回目

太丸は3回重なりました。
とここまでは完全に直線を求める時の説明と同じです。ただ「とある点に接する円」を式で表すのはとても難儀です。上記で示したように中心座標と半径を定数にした方が明らかに表現がしやすいです。
なので通常は円を描画している候補となる点を「中心」とした半径rの円の式で表現し、それらの交点を求めることで、検出したい円の「中心」を求めます。
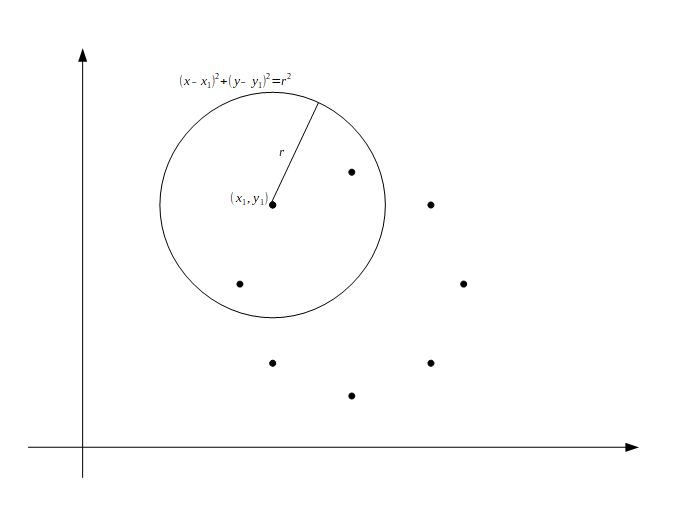
このように円の候補点\(x_1,y_1\)から半径rの円を描画します。黒点は検出したい円の円周上の点とします。
次の候補点\(x_2,y_2\)から同じように半径rの円を描画するととある2点で交わります。
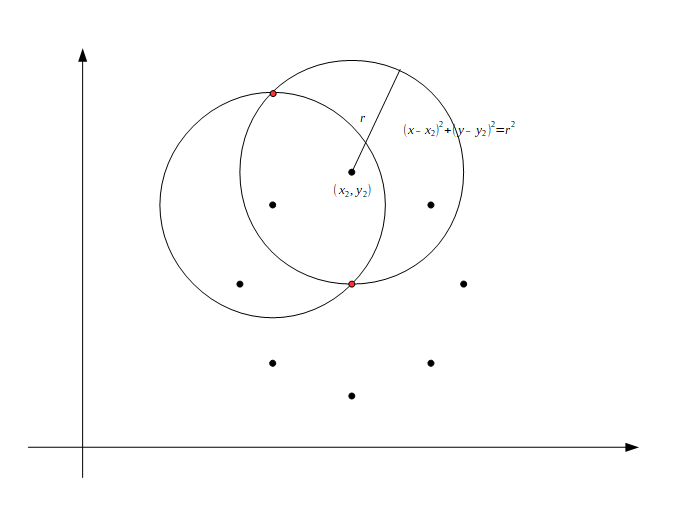
これが見つけたい円の中心候補の点になります。これをすべての候補点で繰り返し、最も交わった回数の多い座標がその候補点で描画される円の「中心」になります。
ひたすら繰り返します。

動きがあった方が分かりやすいですよね。すべての円で交差する点(赤点)が検出したい円の中心になります。
ただこれは半径rが固定で分かっている場合の例で、通常円の半径すら未知であることが多いです。そのためあるレンジでrの大きさを色々変えて、最も交点の個数が多いものがその画像に含まれる中心と半径になります。
とてつもなく計算量が必要です。候補点1つに対して、円を描画し、その円周上の座標(どこのx,yを通ったか)をカウントし、次の候補点に移る。これを複数の半径で行うので、計算量は膨大です。
また円の場合は半径が大きいほど交わる回数が多いため小さい円を見落とさないようにする必要があります。半径でカウント数を正規化する必要もありそうです。
Hough Gradient Method
OpenCVではこんな膨大な演算をしていないと思われます。APIを説明したドキュメントを見るとmethodとしてHough Gradient Methodという手法を使っているそうです。これが計算節約術だと思われます。
ここのサイトにそれっぽい解説がありました。英語ですけど…。
半分推測ですが、ここで行われている計算のケチり方に関して考察してみます。
それっぽい論文は見つかるのですが、コレという確信が持てないので間違ってるかもしれませんが、まぁ大外しはしてないと思います。
勾配を求める必要があるので、この処理では円周の候補点(2値画像)ではなく、円そのものの画像が入力として必要になります。そのうえでエッジの向きを何らかフィルタを使って求めます。
今回はグレーの円を見つけるものとします。これまでの解説ではこのグレーの円に対してCanny() エッジ検出器等を使って、円周だけ事前に抽出された物を入力として想定していました。今回はエッジ検出前の中塗りされた画像そのものになります。

円周上のある点を局所的にみると白からグレーへの傾斜の向きが求められます。
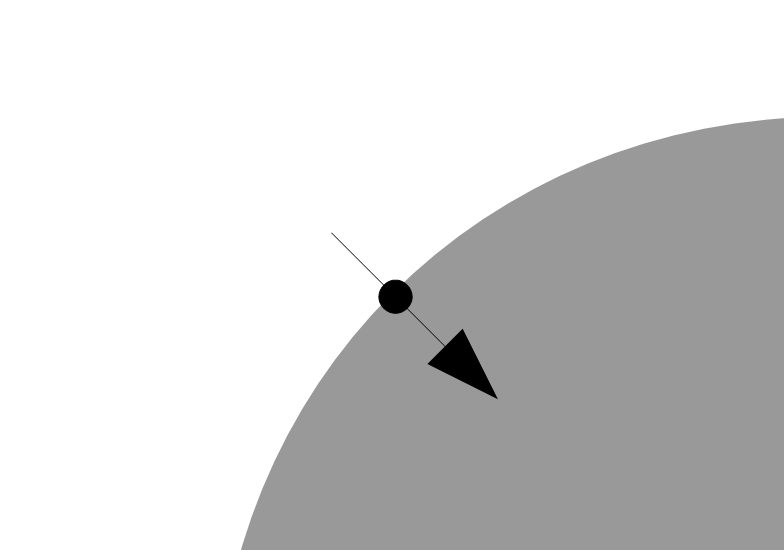
この傾斜の向きに円の中心があることが予想されます。

そのためこの円の中心を求めるための円描画(カウント)はその向きだけで良いであろうことが予想できます。なのでくそ真面目に円周全点を求めるのではなく、勾配から求まる一部を使うことで計算量を飛躍的に小さくすることができるようになります。

↑これが↓これなので走査範囲はこの場合半分
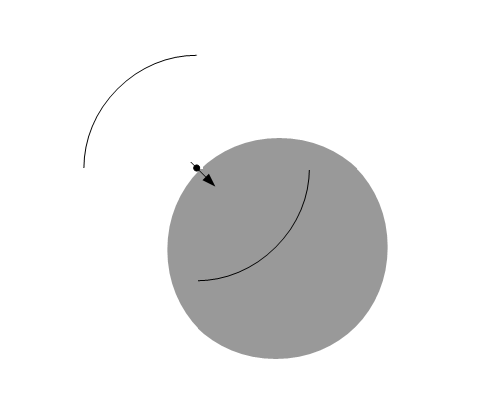
多分そんなところだと思います。コード見ればよいのでしょうけどね。
Pythonにて検算
Python+OpenCVにはこのハフ変換をやってくれる関数が用意されています。自分でコーディングする必要はありません。OpenCVの cv2.HoughCircles()で実装されています。使い方は色々なサイトで紹介されているので細かくは解説しません。
前述の様にこの関数の引数はエッジ検出器を通す前のグレースケール画像になります。この辺りHoughLines()とは異なります。
内部ではCannyエッジ検出器を使っているようで、そのパラメータも引数で渡す必要があります。
Linesと同様にカウント結果(投票箱)は返してくれません。最頻の中心座標と半径を返してくれるだけです。
今回もまた適当なグレーの円をいくつか書いた画像でテストしてみます。線の時とは異なり2値化してません。

640×480画素のグレースケールで、半径100の円を1つ、半径100の円を一部重ねたものを2つ、半径200の円を半分にしたものを1つおいてみました。円の候補は4つ出ることを期待しています。
コードです。
import cv2
import numpy as np
img = cv2.imread("fig11.png")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
thres = 0.99
circles = cv2.HoughCircles(gray, cv2.HOUGH_GRADIENT_ALT, dp=1, minDist=10, param1=100, param2=thres, minRadius=90, maxRadius=220)
print(thres)
print(circles)
method=で指定できる手法は、HOUGH_GRADIENTとHOUGH_GRADIENT_ALTの2種類あるようです。手法によって引数の意味が異なります。
引数のparam2=thresが閾値でdocumentを見るとその意味は
円の中心を検出する際の投票数の閾値を表します.これが小さくなるほど,より多くの誤検出が起こる可能性があります.より多くの投票を獲得した円が,最初に出力されます.
とあります。値が小さいほど多くの円候補が見つかり、昇順で円としての信頼性の高いものから順に出力されるのかなと想像してしまいます。
色々不可解です。基本的には線を検出した時と同様に投票数の多い(信頼性の高い)候補順にListが作られてそうなのですが、必ずしもそのようになっていない場合もあるように見えます。
HOUGH_GRADIENT
まずはHOUGH_GRADIENT法を使ってみます。閾値を徐々に大きくし候補を絞っていきます。
閾値50の時はリストの下の方にゴミ候補が出てきているので返り値の順序としては正しそうです。半径200の半円が1番候補、半径100でどこも欠けてない円が2番候補に挙がっています。
thres = 50
[[[221.5 268.5 200.2] ←半円
[149.5 154.5 100.2]
[392.5 154.5 100.1]
[527.5 227.5 100.1]
[209.5 280.5 183.3] ←ゴミ
[233.5 280.5 183.7]]] ←ゴミ
閾値80でも同様です。なので半径200の半円が半分欠けてるくせに一番候補なのかな?と思ったら
thres = 80
[[[221.5 268.5 200.2] ←半円
[149.5 154.5 100.2]
[392.5 154.5 100.1]
[527.5 227.5 100.1]]]
閾値100にすると半円は候補から消え、半径100の円の円だけになっています。
thres = 100
[[[149.5 154.5 100.2]
[392.5 154.5 100.1]
[527.5 227.5 100.1]]]
閾値130にするとキレイに円が描けている半径100の円だけになっています。
thres = 130
[[[149.5 154.5 100.2]]]
閾値の意味がよくわかりません。閾値50の結果を見ても半径が大きい順というわけでもなさそうです。キレイに描けていない円を抽出する時、ないし抽出したくない時、それぞれどのような値を指定すればよいのだろう…。
半径が既知で特定の大きさの円を見つけたいときにはこの手法で、閾値を調整する必要がありそうです。
HOUGH_GRADIENT_ALT
続いてHOUGH_GRADIENT_ALTの方を使ってみます。こちらの投票は1に近いほど完全な円という意味のようでで、1より小さい値を閾値として指定するようです。円周が長い(半径が長い)方が投票数が増えるので、何ぞ正規化して半径の長さに依存しないようにしていることが予想されます。
こっちはこっちでまた違った順に答えを返してくれます。同じように閾値をじょじょに1に近づけます。
閾値0.9を指定すると半径100のキレイな円を第1候補、半径200の半円を第2候補にして4つ。まぁ思惑通りです。
thres = 0.9
[[[149. 154. 100.05449]]
[[222. 289. 187.6503 ]] ←半円
[[392. 155. 99.99919]]
[[528. 227. 99.96623]]]
閾値を0.99と少し厳しくすると、半径200の円は消え、また微妙に順序と半径の大きさが変化しました。円として欠けが大きいものを候補から除外してくれる。という意味ではいいのですが閾値を変えただけで候補順が変わる挙動はよくわかりません。
thres = 0.99
[[[149. 154. 100.05449]]
[[528. 227. 99.96623]]
[[392. 155. 99.99869]]]
最後閾値を0.999にするとキレイな円だけが残ってます。がまた微妙に半径が変わっています。
thres = 0.999
[[[149. 154. 100.09055]]]
なかなかくせ者です。未知で複数の半径の円が混在する場合にはこちらのHOUGH_GRADIENT_ALTの方が向いているかもしれません。がよくわからん。
返り値の順序のルールがよくわからないです。閾値によって投票の方法が変わっているのかな…。閾値を一番厳しくすると半径100のキレイな円だけが残る。という意味では共通してますが閾値を緩くしたときのListの先頭とは一致しません…。
まとめ
ハフ変換による円検出の仕組みについて色々考えてみました。正確ではないかもしれませんが、大外しもしていないと思います。
ただPythonというかOpenCVの動きはうまく解釈できませんでした。使うときはもう少し色々調べながらパラメータをチューニングする必要がありそうです。
コメント