手持ちで撮影した複数枚連写写真の位置合わせを、PythonとOpenCVを使って行います。手持ちなのに、三脚使って連写したような画像を作ることが目的です。被写体も静止物と、微小な動きを伴ったものとを対象としていろいろ試した結果をまとめてみます。

このRenaさんをLenaさんに合わせて変換する。そんな処理です。どーでもいいですが、正解はLenaさんのようです。
これまでいろいろとスマホ、手持ち、オート、連写、で撮影した写真をソースにその合成をすることで画質の改善だったり、ちょっとしたエフェクトで遊んでました。

その際ポイントとなる画像処理の一つが、撮影した複数枚の写真の位置合わせです。そのまとめをします。
位置合わせ
連写した写真では、ある2枚の画像が時間的に離れている瞬間を撮影したものになります。その間カメラか被写体、あるいはその両者が動くことで、撮影された画像が微妙にずれます。このずれ方も、上下左右のシフト成分だけでなく、回転やあるいは拡大縮小も起こっている可能性があります。
このずれを補正する処理になります。これを補正して、あたかも三脚で撮影したかのような、動きが無い2枚の画像を作り、それらを合成することで、各種効果が得られます。
その位置合わせですが、いろいろ小難しい処理が必要になります。が、一番難しい部分はOpenCVが何とかしてくれます。中身を細かく理解しようと思うと論文行きですが、アプリケーションとして使うだけなら難しいことはありません。
ざっくりとは、ある画像から特徴的な箇所 (画像のエッジとか角とか) とその特徴量(傾斜とか)を求め、 別の画像からそれと同じ特徴を持つ箇所を見つけ出す。といった内容です。
この特徴量が、回転だったり拡大縮小、明るさの変化に対してロバストなすごい処理をどこかの天才が考え、どこかの天才がOpenCVに実装してくれているので、凡人はそれを使って遊ぶことができます。
静止物を対象とした場合、このOpenCVに実装されている関数を基本そのまま使うだけで、あらかたできてしまいます。複数の動体を対象とした場合はもう少し工夫がいります。
今回の実験に用いた写真は、スマホで、手持ちで、オートで、連写。なので手振れもあり、シャッター速度も環境によってまちまちです。ただ1枚1枚の写真はぶれていないことを前提としています。
静止物を被写体とした位置合わせ
いろいろなホームページで紹介されています。OpenCVのオフィシャルでも紹介されています。SIFTベースのアルゴリズムを使うものです。

ここを読むとわかった気になります。
ただこのSIFTは特許を取られているようで、OpenCVデフォルトでは動いてくれません。そこでパテントフリーな類似アルゴリズムであるAKAZEの方を使います。これだと追加インストールは不要です。関数のAPIが完全に同じなので簡単に性能比較もできそうです。
コードを使って流れを説明します。関数を3つ作ってみました。
まずベースとなる、位置を合わせられたい方の画像の特徴量とその位置を取得します。この関数のインターフェースとしては、特徴量を求めたい画像の座標も指定するような作りにしています。画像の一部(例えば被写体の顔とか)を位置合わせしたい時を想定した引数です。座標を指定した部分位置合わせです。
##
# @file alignment.py
# @date 2020/4/14
# @brief 複数画像の位置合わせモジュール
import cv2
import numpy as np
##
# @brief AKAZEによる画像特徴量取得
# @param img 特徴量を取得したい画像(RGB順想定)
# @param pt1 特徴量を求める開始座標 tuple (default 原点)
# @param pt2 特徴量を求める終了座標 tuple (default None=画像の終わり位置)
# @return key points
def get_keypoints(img, pt1 = (0, 0), pt2 = None):
if pt2 is None:
pt2 = (img.shape[1], img.shape[0])
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
mask = cv2.rectangle(np.zeros_like(gray), pt1, pt2, color=1, thickness=-1)
sift = cv2.AKAZE_create()
# find the key points and descriptors with AKAZE
return sift.detectAndCompute(gray, mask=mask)
どこぞのサンプルソースのままです。マスクの機能を使って、領域を絞っています。画素値が1(非ゼロ)のところだけ特徴量を出してくれるようです。rectangleのマスクを作っています。この関数の使い方としては、
kp, des = alignment.get_keypoints(base,(1406, 741), (2226, 2622))
こんな感じを想定しています。特徴量とその座標を取っときます。
続いて、位置を合わせたい方の画像の特徴点を求め、先の特徴点とマッチングを取りますす。やはり公式にチュートリアルがあり、
これを読むとわかった気になります。
この関数は一致した座標列のペアを返します。
##
# @brief imgと、特徴記述子kp2/des2にマッチするような pointを求める
# @param img 特徴量を取得したい画像(RGB順想定)
# @param kp2 ベースとなる画像のkeypoint
# @param des2 ベースとなる画像の特徴記述
# @return apt1 imgの座標 apt2 それに対応するkp2
def get_matcher(img, kp2, des2):
kp1, des1 = get_keypoints(img)
if len(kp1) == 0 or len(kp2) == 0:
return None
# Brute-Force Matcher生成
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
# store all the good matches as per Lowe's ratio test.
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
if len(good) == 0:
return None
target_position = []
base_position = []
# x,y座標の取得
for g in good:
target_position.append([kp1[g.queryIdx].pt[0], kp1[g.queryIdx].pt[1]])
base_position.append([kp2[g.trainIdx].pt[0], kp2[g.trainIdx].pt[1]])
apt1 = np.array(target_position)
apt2 = np.array(base_position)
return apt1, apt2
これもどこぞのサンプルソースのままです。閾値等最適化してません。
これで、対応する座標のペアが取得できるので、そのペアから変換行列を求めます。今回はアフィン変換にします。一応射影変換も試したのですが、それほど差が出なかったので。あとバイリニアにしてます。Cubicの方がいいかもしれません。
##
# @brief マッチング画像生成(kp2にマッチするような画像へimgを変換)
# @param img 変換させる画像(RGB順想定)
# @param kp2 ベースとなる画像のkeypoint
# @param des2 ベースとなる画像の特徴記述
# @return アフィン変換後の画像 (行列推定に失敗するとNoneが返る)
def get_alignment_img(img, kp2, des2):
height, width = img.shape[:2]
# 対応点を探索
apt1, apt2 = get_matcher(img, kp2, des2)
# アフィン行列の推定
mtx = cv2.estimateAffinePartial2D(apt1, apt2)[0]
# アフィン変換
if mtx is not None:
return cv2.warpAffine(img, mtx, (width, height))
else:
return None
失敗するとNoneを返す仕様にしました。
この行列推定の関数ですが、昔はestimateRigidTransformという関数数だったようですが、新しいOpenCVのバージョンだと使えなくなっているみたいです。 昔は
mtx = cv2.estimateRigidTransform(apt1, apt2, False)
こんな感じ。世の中このサンプルは多く見かけますが、最近は
mtx = cv2.estimateAffinePartial2D(apt1, apt2)[0]
こっちです。精度はわかりません。以下で少し動きを確認しています。

最終的にはこんな感じで関数コールしてやります。
base = np.array(Image.open("IMG_2169.JPG"), dtype=np.uint8)
frame = np.array(Image.open("IMG_2170.JPG"), dtype=np.uint8)
kp, des = get_keypoints(base,(1406, 741), (2226, 2622))
align = get_alignment_img(frame, kp, des)
Image.fromarray(align).save("IMG_IMG_2169_align.JPG", "JPEG")
これでbaseに位置が一致したframeが得られます。baseの特徴量取得を別関数にしているのは、2枚以上の画像をソースとした際に、毎度毎度baseの画像の特徴量を取得してたら処理時間かかってしょうがないので残しておくことにします。
これで静止物を撮影したときの複数枚位置合わせは、ぼちぼちうまく行きます。
複数の動体を対象とした位置合わせ
こちらが難儀です。複数の動きを伴う連続画像を対象とすると、画像全体に対するアフィン変換や射影変換では対応できません。また、画像間の視差が大きいものもイマイチです。クールなのは機械学習から推定させるのかもしれませんが、今回は泥臭く行きます。
以前の記事で、やってみた処理です。位置合わせの部分だけまとめます。

基本思想は、小領域に分割して、その小領域単位で変換と微小位置合わせを繰り返すものです。隣接フレーム間の
・動きは小さい。
・画角はほとんど変化がない。
を仮定します。あるベース画像と類似した隣接フレームの画像を取得し、位置合わせをします。言ってしまえばブロック単位に位置合わせをするだけ。
処理の大雑把な流れとしては、
小領域毎にアフィン行列推定
さらに小さいブロック単位にアフィン行列補間
ブロック単位にアフィン変換
ブロック単位にパターンマッチング
の大きく4つの処理をして細かく位置合わせをしていきます。
まず全体に対して、静止物同様にAKAZEを使って、2枚の画像の特徴点ペアを作ります。上記静止物を対象とした処理と同じ関数です。
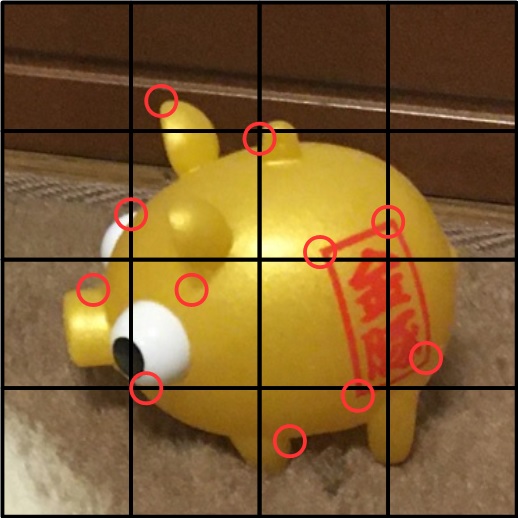
静止画を対象とした際は、ベースの画像と合わせたい画像で、画像単位のマッチングを行っていましたが、合わせたい画像の方を16分割した小領域に分け、それぞれの小領域単位にマッチングを取ることにします。小領域の特徴量とベース画像の特徴量をマッチングし、その小領域ごとにアフィン行列を求め、16個のアフィン行列の列を作ります。

その後、画像をさらに細かく、ブロック(図では32×32画素)単位に分けます。そのブロック単位のアフィン行列を、マッチングで求めた16個のアフィン行列から補間します。

ここまでの処理で、各ブロックのアフィン行列が求まりますので、その行列を使ってアフィン変換を行います。これでブロック単位の画像がモザイク状に位置合わせがされます。

微小な回転を伴っているイメージ。これに対して、さらにパターンマッチングを使って微調整をします。今回はブロックそのものをテンプレートに、上下左右32画素ずらしながら、最も相関が高い位置を探します。
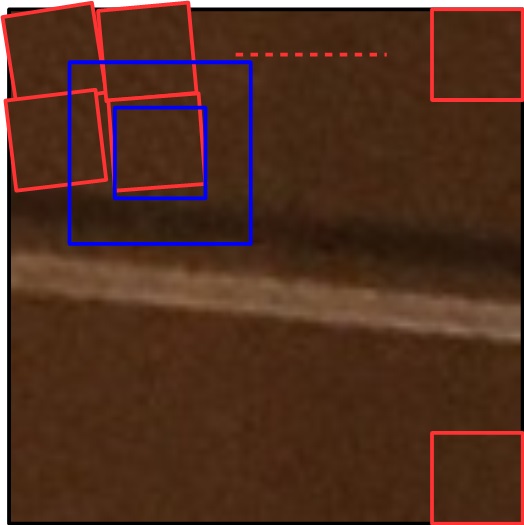
青い箇所が探索範囲で、その範囲をOpenCVの力を借りてパターンマッチングしています。
このままだと、ブロック境界がはっきりと見えてしまったので、ブロック開始座標をずらせるような作りにしました。複数枚合成する際に、そのブロック開始位置をずらしながら合成することで境界をぼかして目立たなくさせることができます。
コードとしては、まずは小領域毎のアフィン行列推定
##
# @brief 指定された座標の範囲にあるpoint1のマッチングポイントを切り出す。
# @param start 切り出したいpoint1の開始座標
# @param end 切り出したいpoint1の終了座標
# @param pt1 切り出したい points1
# @param pt2 切り出したい points2
# @return 切り出されたkey points
def trim_point(start, end, pt1, pt2):
tmp = np.where((start[0] < pt1) && (pt1 < end[0]))
indx = tmp[0][np.where(tmp[1] == 0)]
ptx1 = pt1[indx]
ptx2 = pt2[indx]
tmp = np.where((start[1] < ptx1) && (ptx1 < end[1]))
indx = tmp[0][np.where(tmp[1] == 1)]
apt1 = ptx1[indx]
apt2 = ptx2[indx]
return apt1, apt2
##
# @brief 指定された座標の範囲でpoint1へのアフィン行列を推定する
# @param start 切り出したいpoint1の開始座標
# @param end 切り出したいpoint1の終了座標
# @param pt1 切り出したい points1
# @param pt2 切り出したい points2
# @return 変換行列
def get_affine_mtx_partial(start, end, pt1, pt2):
apt1, apt2 = trim_point(start, end, pt1, pt2)
# もし8以下しかマッチするポイントが無い場合は信頼性が低いと判断
if len(apt1) < 8:
apt1 = pt1
apt2 = pt2
return cv2.estimateAffinePartial2D(apt1, apt2)[0]
続いて、 ブロック単位にアフィン変換+パターンマッチング。
##
# @brief ブロックマッチングしマッチングが取れたimg1のブロックを返す <br>
# (img1の一部をaffine変換したうえで、img2とパターンマッチングして微調整)
# @param sx 切り出したいimg2基準の開始x座標
# @param sy 切り出したいimg2基準の開始y座標
# @param width ブロックの幅
# @param height ブロックの高さ
# @param mtx 指定座標における img2ブロックへのimg1ブロックの変換行列
# @return img2の指定座標に最もフィッティングしたimg1のブロック
def get_affine_img_partial(sx, sy, width, height, img1, img2, mtx):
# 上下左右に対するオフセット(探索範囲)
ofst = 32
# アフィン行列のシフト成分をオフセット
mtx[0, 2] -= (sx - ofst)
mtx[1, 2] -= (sy - ofst)
# ブロックサイズよりofst*2大きくなる
resz = cv2.warpAffine(img1, mtx, (width + 2 * ofst, height + 2 * ofst))
ex = sx + width
ey = sy + height
template = img2[sy:ey, sx:ex, :]
res = cv2.matchTemplate(resz, template, cv2.TM_SQDIFF)
min_val, _, min_loc, _ = cv2.minMaxLoc(res)
# あまりに値が大きい場合にはimg2のテンプレートを返す
if min_val > 1000000:
return template
else:
return resz[min_loc[1]:min_loc[1] + height, min_loc[0]:min_loc[0] + width, :]
最後に画像に対してブロック分割する処理。ココでブロック開始位置をずらしたり、16個のアフィン行列を拡大したり、ブロック分割したりしてます。
##
# @brief ブロック単位にimg2にマッチングしたimg1の変換画像を返す
# @param img1 変換したい座標
# @param img2 位置合わせをしたい画像
# @param apt1 img1のkeypoints
# @param apt2 img2のkeypoints
# @param ofst ブロック探索開始位置のオフセット (default 0,0)
# @param block ブロックサイズ (default 32)
# @return img2にブロック単位でフィッティングさせimg1
def get_block_match_img(img1, img2, apt1, apt2, ofst=(0, 0), block=32):
height, width = img1.shape[:2]
tmp = img2.copy()
w = width // 4
h = height // 4
affinarray = []
# 4x4の16分割して、それぞれの領域でアフィン行列を求める
for y in range(4):
for x in range(4):
sx = x * w + ofst[0]
sy = y * h + ofst[1]
tform = get_affine_mtx_partial((sx, sy), (sx+w, sy+h), apt1, apt2)
if tform is None:
return img2
affinarray.append(tform.reshape(6))
# 32x32画素単位で画像の位置合わせをしていく
w = (width-ofst[0]) // block
h = (height-ofst[1]) // block
# 4x4のアフィン行列群をブロック毎の行列へ展開(拡大)
affinarray = np.array(affinarray).reshape(4, 4, 6)
affinarray = cv2.resize(affinarray, dsize=(w, h), interpolation=cv2.INTER_NEAREST)
# ブロックマッチング
for y in range(h):
for x in range(w):
sx = x * block + ofst[0]
sy = y * block + ofst[1]
tmp[sy:sy + block, sx:sx + block, :] = get_affine_img_partial(sx, sy, block, block, img1, img2,
affinarray[y][x].reshape(2, 3))
return tmp
最後のこれが外部APIのイメージ。先の静止画を対象としたそれと似た見た目にしています。
##
# @brief マッチング画像生成(kp2にマッチするような画像へimgを変換)
# @param img1 変換させる画像(RGB順想定)
# @param img2 ベース画像(位置合わせさせる対象)
# @param kp2 ベースとなる画像のkeypoint
# @param des2 ベースとなる画像の特徴記述
# @return ブロック単位の変換画像
def get_alignment_img2(img1, img2, kp2, des2, ofst=(0, 0), block=32):
pt1, pt2 = get_matcher(img1, kp2, des2)
return get_block_match_img(img1, img2, pt1, pt2, ofst, block)
結果
ノイズを重畳したLenaさんと、傾き縮みほくろが2つついたRenaさんを用意しました。このRenaさんをLenaさんに位置合わせします。文字の位置も微妙にずらしてます。画像サイズは512×512 pixel。

これくらいずれてて、これくらいLenaさんにはノイズが乗っています。

上記の関数群をalignment.pyとして外部ファイルにしたものをimportして使ってみました。
from PIL import Image
import numpy as np
import alignment
base = np.array(Image.open("lena.JPG"), dtype=np.uint8)
frame = np.array(Image.open("rena.JPG"), dtype=np.uint8)
kp, des = alignment.get_keypoints(base)
align = alignment.get_alignment_img(frame, kp, des) # 静止物対象処理
align2 = alignment.get_alignment_img2(frame, base, kp, des) # 動体対象処理
Image.fromarray(align).save("aligned_rena1.JPG", "JPEG", quality=95)
Image.fromarray(align2).save("aligned_rena2.JPG", "JPEG", quality=95)
静止物を被写体とした処理結果
まず静止物を対象としたシンプルな位置合わせの結果です。


気持ちいいくらいに位置が合いました。これくらいのノイズはなんてことはないですね。当たり前ですが、ほくろが消えたりRがLになるようなこともないです。
複数の動体を対象とした処理結果
で動体を対象にした位置合わせの結果です。

一見見分けがつきません。ほくろが消え、RがLになっています。また隅っこの黒もなくなりました。拡大します。

ほくろの箇所です。消えたほくろは別の頬っぺたの箇所から補われました。見事にブロック状の影が見えます。鼻のエッジがずれています。

おでこのほくろの箇所は、近隣にマッチするブロックが見当たらなかったため、オリジナルのノイジーな箇所がそのまま使われています。ノイズブロックが出ています。

文字部も同様。RとLで大外れしているのでオリジナルのノイジーブロックが使われています。aとかはRenaさんの方使ってもらえるかなぁと思ったのですが、文字をずらし過ぎたかもしれません。

右下隅っこ。Renaさんの方には情報が存在しない箇所です。まったくない箇所はオリジナルのノイジーブロック、少し残っている箇所はブロック単位の位置合わせをしたうえで補っている様子が、ブロック状のスジとしてわかってしまいます。
まとめ
複数枚の連写写真を想定して、位置合わせを行い、あたかもカメラを三脚固定したかのような画像を作り出すことができました。
が、動体を対象としたブロック単位のマッチングではブロック境界が見えてしまいました。しょうがない。一応この対策として、ブロック開始座標をずらせるような関数にもしてあるので、ずらしながら複数回処理することで境界は幾分見えにくくなります。が処理は重たくなります。
静止物を被写体とした時と、動体を被写体とした時で使い分ける必要があります。これらの処理で得られたずれの無い画像を元に、複数枚画像合成をすることで、いろいろ遊べます。この合成の処理で、上記のように出てしまったブロック状のノイズは消し去ります。なのでいったんこの段階でブロックが見えるのはしょうがないとします。
合成の処理に関しても考察してみます。
位置が合っている前提のシンプルな合成と、手持ち、動体を対象にした合成とまとめてみました。


コメント
写真画像の位置合わせのコード、素晴らしいものでした。
get_affine_img_partial関数のtemplateの色を判定させて、get_alignment_img2のbaseとframeを逆にすると、「別物だけど似た写真」の間違い探しができました。
このようなコードを効果してくださりありがとうございます。
お礼まで。