Tensorflow+Kerasの環境を作って、いわゆるHello World的なことをするための覚書
Tensorflowのインストール
もともと別々のものだったKerasとTensorflowですが、今はTensorflowにKerasは組み込まれているようです。もともとKerasはWrapperライブラリだったんですね。
汚れた環境でインストールするのも何なので、きれいな環境を作ってから作業を行います。コマンドラインから
python -m venv keras_env
で新しい環境を用意します。そこからScript/activateを実行してkeras_env環境に入ります。ひとまず
python -m pip install --upgrade pip
でpipをアップグレードしときます。あとついでに必要になる
pip install matplotlib
そして本命のTensorflowをインストールします。
pip install tensorflow
インストール作業は結構長いことかかりますが、辛抱強く待ちます。今回のPCにはGPUは入っていないので、ひとまず本体のインストールはここまで。
Hello Tensorflow World
ひとまずどこかのWebに落ちてた代表的なテストコードを少し加工したものを動かします。
mnistからダウンロードしてきたラベル付き手書き文字(数字)画像群の分類問題です。どメジャーな奴ですね。
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Activation, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
# 画像と正解ラベルの読み込み(訓練データ60000枚とテストデータ10000枚)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 最初の6枚だけ画像の表示
fig = plt.figure()
for i in range(6):
fig.add_subplot(2,3,i+1)
plt.imshow(X_train[i], cmap = "gray")
# 画像データの並び替え(60000x28x28 -> 60000x784x1)
X_train = X_train.reshape(X_train.shape[0], 784)
X_test = X_test.reshape(X_test.shape[0], 784)
# 正解ラベルの変換(one-hotベクトル化)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# レイヤを順繰りに連続的に重ねる
model = Sequential()
model.add(Dense(256, input_dim=784)) # 1層目 画像が784画素あるので全部入力するとこのサイズ
model.add(Activation("sigmoid")) # 活性化関数はsigmoid
model.add(Dense(128)) # 2層目
model.add(Activation("sigmoid"))
model.add(Dense(10)) # 3層目 10クラスに分けるので最終層は10
model.add(Activation("softmax")) # 最終層はsoftmax(合計1の確立表現させるため)
# optimizer:sgd 確率的勾配降下法
# loss 損失関数:categorical_crossentropy (多クラス分類問題の正解データ(ラベル)を、one-hot表現(one-hotベクトル)で与えている場合に使用)
# metrics 評価関数:ひとまず自動acc
model.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["acc"])
# epochsを3回
model.fit(X_train, y_train, epochs=3)
plt.show()
これだけで動いてしまいます。これを実行すると何ぞログが表示され学習が進みます。
Epoch 1/3
1875/1875 [==============================] - 3s 1ms/step - loss: 1.1030 - acc: 0.7738
Epoch 2/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.4322 - acc: 0.8967
Epoch 3/3
1875/1875 [==============================] - 2s 1ms/step - loss: 0.3297 - acc: 0.9135
よくわかりませんがどうやら最後には訓練データで正答率が91%まで行ったようです。
コードの解説
コードにコメント入れたので繰り返しになりますが、一応確認していきます。
# 画像と正解ラベルの読み込み(訓練データ60000枚とテストデータ10000枚)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
まずは画像を読み込みます。7万枚の28x28pixelの画像をネットからダウンロードして使います。最初こそ遅いですが、どっかにキャッシュされて次以降は高速に読み込みます。
自動的に訓練用とテスト用の2分割してくれます。自動で6:1に割り振ってくれるようです。
最初の6枚だけ表示させると

こんな感じ
続いて画像データを並び替えします。
# 画像データの並び替え(60000x28x28 -> 60000x784x1)
X_train = X_train.reshape(X_train.shape[0], 784)
X_test = X_test.reshape(X_test.shape[0], 784)
6万枚の28x28pixelの2次元の画像データを1次元に並び替えます。これは1層目のノードに渡すための並び替えです。
次に正解ラベルを変換します。
# 正解ラベルの変換(one-hotベクトル化)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
もともと手書き文字の正解値が1次元配列でずらっと入っているデータです。
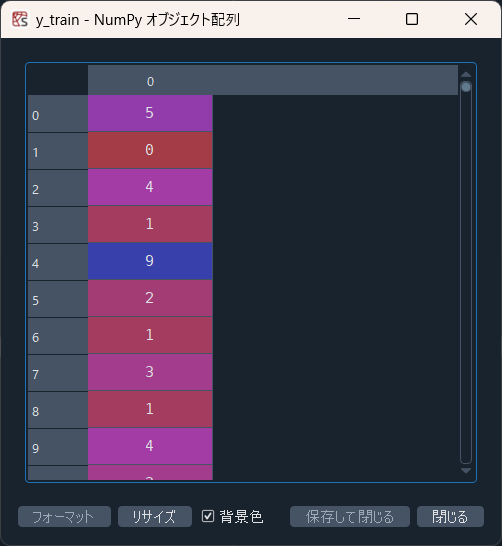
こんな感じ。これをone-hot表現の配列(ベクトル)に変換してやります。0/1の配列で、正解の位置に1が立ち、それ以外では0となる配列です。こんな感じ。
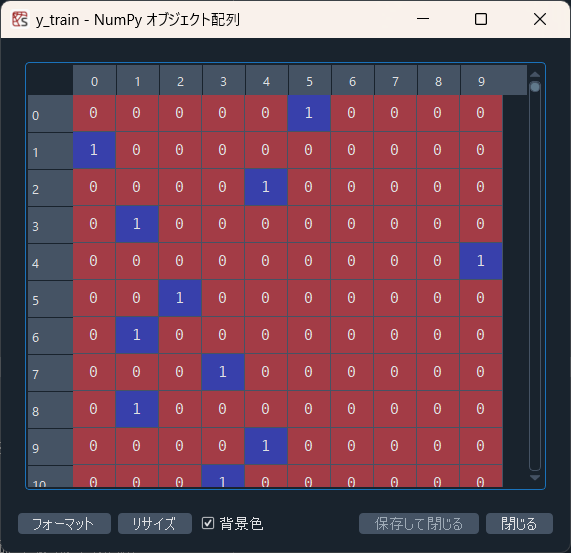
1行目のように、正解が5であれば、配列の5番目だけ1になり他は0になっています。
次からがいよいよネットワークを作っていきます。
# レイヤを順繰りに連続的に重ねる
model = Sequential()
model.add(Dense(256, input_dim=784)) # 1層目 画像が784画素あるので全部入力するとこのサイズ
model.add(Activation("sigmoid")) # 活性化関数はsigmoid
model.add(Dense(128)) # 2層目
model.add(Activation("sigmoid"))
model.add(Dense(10)) # 3層目 10クラスに分けるので最終層は10
model.add(Activation("softmax")) # 最終層はsoftmax(合計1の確立表現させるため)
ひとまず順繰りに層を重ねます。3層で、1層目が入力画像を1次元にした784ノードを持つ層、2層目が128ノード、最終層が10個のクラス分けのため10ノード。
それらの間を活性化関数ではさみます。今回はsigmoidと最後softmax。reluだのsigmoidだのはひとまず適当です。最後だけは10個のクラスの確率表現にしたいので、softmaxです。このあたり詳細はググってください。
もっともらしく図にするとこんな感じ
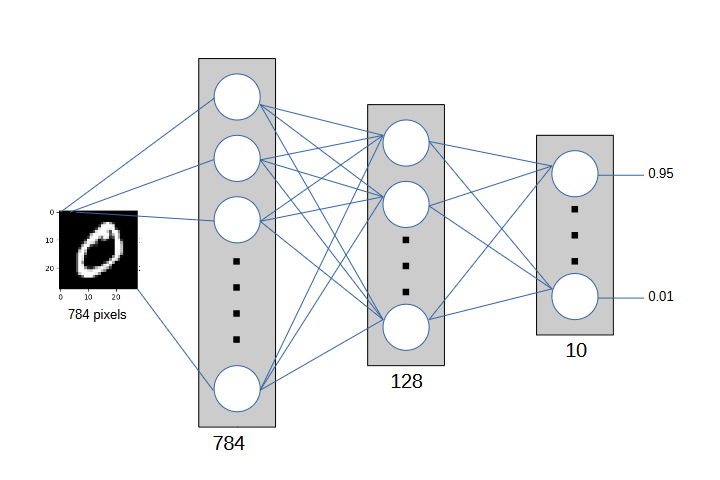
最後に最適化のための設定をします。どんな方法で、どんな損失関数で、どんな評価関数で最適化するかを設定するようです。詳細は調べるしかなさそうです。
# optimizer:sgd 確率的勾配降下法
# loss 損失関数:categorical_crossentropy (多クラス分類問題の正解データ(ラベル)を、one-hot表現(one-hotベクトル)で与えている場合に使用)
# metrics 評価関数:ひとまず自動acc
model.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["acc"])
今回はコードでコメントした通りの設定で動かします。
# epochsを3回
model.fit(X_train, y_train, epochs=3)
今回は3周回してみました。
おわりに
いったん最小限のコードで層を作って、文字認識するためのネットワークを作って訓練だけさせました。どんな推論をするか結果は見てません。hello worldなので。
次ではもう少しいじって、推論までさせたコードにします。



コメント