いわゆるHello World的なことをするための覚書。前回それっぽい認識ができたので、続き。
前回のコードをベースにCNNを使ってみます。

mnistの画像を使って、結果として98%の正答率が出せました。
CNN
言わずと知れたConvolutional Neural Networkのことですね。もはや画像認識のいろはになっていますね。
前回までのネットワークでは、画像の2次元の空間的な広がりを無視して1次元の配列として学習をさせていました。(それでもあれだけの認識率(94%前後)が出てしまうのでびっくりですが。)
CNNでは上下左右の空間的な特徴を学習の対象にさせるために2次元の畳み込みを行い、特徴をつかんでいきます。
畳み込み
Convolution。まぁこれはいいか。nxnのフィルタを画像に畳み込んでやることです。各層でとあるサイズのフィルタを畳み込んで次の層に渡します。このフィルタ係数が学習対象になります。
層を重ねる際に
model.add(Conv2D(20))
こんな感じで定義します。この場合は20個のフィルタ。
フィルタサイズ
カーネルサイズとかとも呼ばれます。OpenCVでもおなじみですね。
ある注目画素を中心として上下左右に均等なサイズが定番なので、通常奇数になります。多分縦横好きなサイズが選べると思います。

この例は5×5。記述は層を重ねるタイミングで引数で渡せます。
model.add(Conv2D(20, kernel_size=5))
パディング
画像外の値ですね。フィルタをかける際にどうしても外を参照してしまうケースが出るので、その対処です。この図は5×5のフィルタなので2画素外にはみ出ます。

これを対処するか否か。対処しなければ注目画素が2画素画像の内側に入ってきてしまうので結果画像サイズが縮みます。

なので入出力の画像を同じサイズにしたければsameを縮んでもよければvalidを設定すればよさそうです。画像の外は0想定のようです。入力1層目の画像の外は少し気を付けた方がいいかも。続く層ではまぁフィルタ+活性化関数後なのでまぁあまり気にしなくてもよさそう。
フィルタサイズが3であれば、上下左右1画素削れるので、画像サイズはもとより縦横2画素縮みます。フィルタサイズが5であれば4画素縮みます。
model.add(Conv2D(20, kernel_size=5, padding="same"))
ストライド
フィルタのウィンドウを何画素ステップでずらすか。というパラメータですね。通常の画像処理ではまぁ1でしょう。ただ層をまたいだ時に画像サイズを小さくしたければこれを1より大きい数にしてやればよいです。
画像の特徴をとらえたまま小さくしたければ後述のpooling層を足してやるのが一般的みたいですが。
model.add(Conv2D(20, kernel_size=5, padding="same", strides=(1, 1)))
1ずつずらすのであれば引数は省略でよいです。
プーリング層
畳み込み層だけではなく、このプーリング層を足すことで特徴を抑えたままデータ削減を行います。要は画像の縮小処理です。
通常MAXプーリングかAverageプーリングなどがされるようです。
model.add(MaxPooling2D(pool_size=(2, 2)))
こんな感じで層を追加します。
あとのパラメータは前回作ったネットワークと同じなので説明は割愛。最適化の方法や活性化関数、ドロップアウトやそんなのを使って調整します。
Hello Tensorflow CNN World
前回のコードに対して前段にCNNの層を追加します。ちょっと長くなりました。
from tensorflow.keras.datasets import mnist
from tensorflow.keras.layers import Dense, Dropout, Flatten, Activation
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.models import Sequential
from tensorflow.keras import optimizers
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
import numpy as np
# 画像と正解ラベルの読み込み(訓練データ60000枚とテストデータ10000枚)
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# test data 6枚だけ画像の表示
fig = plt.figure()
for i in range(6):
fig.add_subplot(2,3,i+1)
plt.imshow(X_test[i], cmap = "gray")
# 画像データの並び替え(60000x28x28 -> 60000x28x28x1)
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
# 正解ラベルの変換(one-hotベクトル化)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# レイヤを順繰りに連続的に重ねる
model = Sequential()
model.add(Conv2D(20, kernel_size=5, padding="same", input_shape=(28, 28, 1)))
model.add(Activation("relu")) # 活性化関数はrelu
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(50, kernel_size=5, padding="same"))
model.add(Activation("relu")) # 活性化関数はrelu
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# ここからは前回作成のネットワーク
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation("sigmoid"))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation("softmax"))
# optimizer:sgd 確率的勾配降下法
sgd = optimizers.SGD(learning_rate=0.01) # 学習率0.01
# loss 損失関数:categorical_crossentropy (多クラス分類問題の正解データ(ラベル)を、one-hot表現(one-hotベクトル)で与えている場合に使用)
# metrics 評価関数:ひとまず自動acc
model.compile(loss="categorical_crossentropy", optimizer=sgd, metrics=["acc"])
model.summary()
history = model.fit(X_train, y_train, batch_size=128, epochs=10, validation_data=(X_test, y_test))
# テスト結果
score = model.evaluate(X_test, y_test, verbose=0)
print("evaluate loss:", score[0])
print("evaluate acc:", score[1])
# 推論結果
result = model.predict(X_test[:6], batch_size=None, verbose=0, steps=None)
print("推論結果:" + str(np.argmax(result, axis=1)))
#accのプロット
plt.figure()
plt.plot(history.history["acc"], label="acc", ls="-", marker="o")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
畳み込み層を2つとpooling層を2つ追加しています。後ろのネットワークは前回のそれとまるで同じ。
これを実行すると
Epoch 1/10
469/469 [==============================] - 9s 18ms/step - loss: 1.8108 - acc: 0.4553 - val_loss: 1.0831 - val_acc: 0.8545
Epoch 2/10
469/469 [==============================] - 9s 19ms/step - loss: 1.0054 - acc: 0.7949 - val_loss: 0.5626 - val_acc: 0.9217
:
Epoch 9/10
469/469 [==============================] - 9s 18ms/step - loss: 0.1667 - acc: 0.9608 - val_loss: 0.0920 - val_acc: 0.9745
Epoch 10/10
469/469 [==============================] - 8s 18ms/step - loss: 0.1488 - acc: 0.9649 - val_loss: 0.0822 - val_acc: 0.9771
evaluate loss: 0.08221150189638138
evaluate acc: 0.9771000146865845
推論結果:[7 2 1 0 4 1]
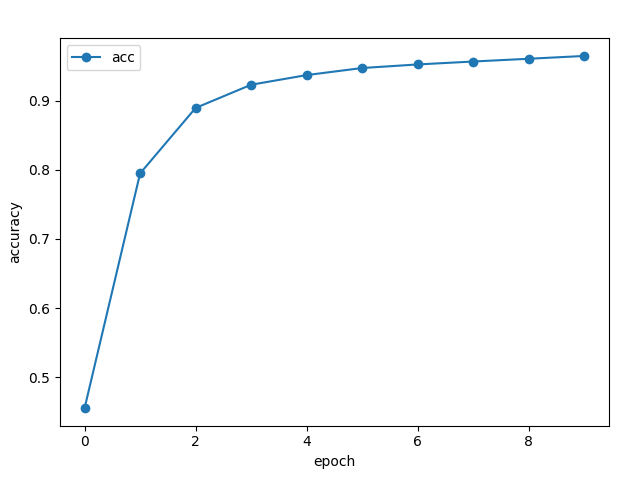
グラフを見るとEpoch数が進むにつれて次第にaccuracyがよくなっていきます。ひとまず96%の正答率で、テスト結果も同97%。いい感じで汎化できてそうです。
推論の結果も、入力の画像が

に対して、結果が
推論結果:[7 2 1 0 4 1]
なので正解です。
学習時間がえらい伸びました。ただ思ったほど正答率が上がった気がしません。(94%→96%)
世のサンプルを眺めると、どうもoptimizerが違うみたいなので、これを倣ってAdamに変えてみました。
sgd = optimizers.Adam()
1行これを書き換えると
Epoch 10/10
469/469 [==============================] - 9s 19ms/step - loss: 0.0523 - acc: 0.9836 - val_loss: 0.0365 - val_acc: 0.9884
evaluate loss: 0.036486461758613586
evaluate acc: 0.9883999824523926
推論結果:[7 2 1 0 4 1]
98%まで伸びました。まぁこのあたりが限界でしょう。
グラフを見るとepochも5あたりでサチってるので、10回も学習する必要なさそうです。
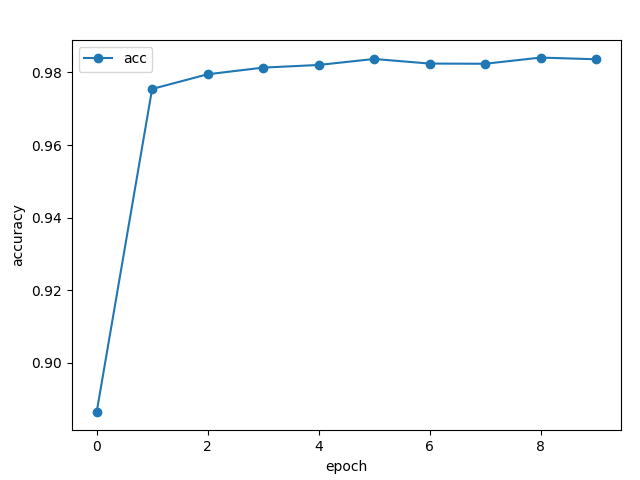
今回の場合はAdamが最適なようです。
ひとまず、3回かけてkerasのインストールからCNNを使うところまで試してみました。簡単に試せておもろかった。

コメント