
もう少し突っ込んだメモ。まだHello World。データの準備や効率よく学習を進めるためのテクニックに関するメモ。
ここをキーワードにググるべし。
データ拡張(Data Augmentation)
今持っている画像データ量が心もとないときに、画像を水ますと正答率を上げることができる。かもしれない。
ただコピーしても意味がないので、画像を反転したり、シフトしたり、回転したり、拡大したり、(いわゆるアフィン変換)します。
このようにして水増しした画像データを細切れ(バッチ)にして返してくれる便利な機能がTensorflow(Keras)にあります。

引数が大量にあります。詳しくは解説しませんが、日本語で解説してくれているページもありそうです。
ココにあるサンプルコードを引用
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)
datagen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
# compute quantities required for featurewise normalization
# (std, mean, and principal components if ZCA whitening is applied)
datagen.fit(x_train)
# fits the model on batches with real-time data augmentation:
model.fit_generator(datagen.flow(x_train, y_train, batch_size=32),
steps_per_epoch=len(x_train) / 32, epochs=epochs)
# here's a more "manual" example
for e in range(epochs):
print('Epoch', e)
batches = 0
for x_batch, y_batch in datagen.flow(x_train, y_train, batch_size=32):
model.fit(x_batch, y_batch)
batches += 1
if batches >= len(x_train) / 32:
# we need to break the loop by hand because
# the generator loops indefinitely
雰囲気はわかります。
正規化
画像データの正規化をしてやることで正答率を上げることができる。かもしれない。
正規化とは一般的に画像の最大値と最小値を0,255にそろえて画像の明るさを整えてやることを指します。こんな感じ。
out = (in - in.min) / (in.max - in.min)
動くコードにすると
# 画像の読み込み
img = cv2.imread("lena2.png", 0)
img = cv2.blur(img, (3, 3))
# ヒストグラムの取得
img_hist_cv = cv2.calcHist([img], [0], None, [256], [0, 256])
img = (((img.astype(np.float64) - img.min()) * 255) / (img.max() - img.min())).astype(np.uint8)
cv2.imwrite("lena2out.png", img)
# ヒストグラムの形を滑らかにするためにぼかし
img = cv2.blur(img, (3, 3))
# ヒストグラムの取得
# img_hist_cv = cv2.calcHist([img], [0], None, [256], [0, 256])
# ヒストグラムの表示
plt.plot(img_hist_cv)
plt.show()
結果がこれ

左が入力、右が出力。コントラストが改善されています。ヒストグラムを見ると、
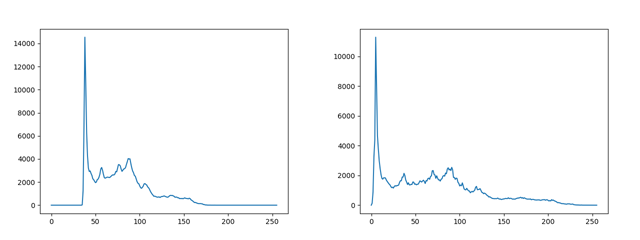
ちゃんと広がってます。
ただネットワークが深ければそれすら乗り越えていくことが多いようです。浅いネットワークの時には有効なようです。
正規化って色々な意味で使われることが多いので都度都度気をつけねばいけません。次の標準化も状況次第では正規化と呼ばれたりするので厄介です。
単純に0~255の整数画素値を0~1の実数画素値へ直すことも正規化と呼んでたりします。これは何も学習精度に影響しないです。
標準化
正規化と響きは似てますが、機械学習の世界では別物です。正規化では画素値の最小・最大から画素値全体を単純に引き延ばすだけですが、こいつは画素の平均を0、分散を1にすることです。
画像よりグラフで見た方がわかりやすい。
特徴をあぶりだすには有効な手段なようです。
これは上記のImageDataGeneratorの引数で指定できてしまいます。
samplewise_center = True
にすると平均をゼロに
samplewise_std_normalization = True
にすると分散(正確には標準偏差かな)を1にしてくれるようです。処理のイメージは
out = (in - in.ave) / in.std
こんな感じ。確かにこうしてやれば平均は必ずゼロで、分散計算すれば必ず1になります。
x = cv2.imread('lena.png')
x = x.reshape((1,) + x.shape)
datagen = ImageDataGenerator(
samplewise_center=True,
samplewise_std_normalization=True)
d = datagen.flow(x, batch_size=1).next()
# 0-255の画像化するための処理
ofs = np.max(d[0])
if np.abs(np.min(d[0])) > ofs:
ofs = np.abs(np.min(d[0]))
cv2.imwrite("lena_standardize.png", (d[0]+ofs)/(2*ofs)*255)
print("std: ", np.std(d[0]))
print("ave: ", np.mean(d[0]))
こいつを実行するときちんと
std: 1.0
ave: 5.6888285e-07
となってました。仕様としてはRGBそれぞれで平均・分散を計算するわけではなく、RGBすべてのデータを使うようです。
ちなみに入出力の画像は

こんな感じ。画像化してもあまり意味ないですね。
同じように
featurewise_center
featurewise_std_normalization
という引数もありますが、これはサンプルセット全体がこうなるように標準化する。ということのようです。多分。きっと。
白色化
上記の標準化に加えて、無相関化することを白色化と呼ぶそうです。このあたりから自分でテストできていないので、「らしい」になってしまうのですが、このテクニックも学習を効率的に進めるために必要な前処理になります。
この無相関にする。という処理がややこしい。一読しただけでは頭に入ってこなかったのでいったんここでの解説は諦めます。
この白色化ですが、
zca_whitening = True
で実現できてしまいそうです。ただ実行すると以下のメッセージが出てしまったので、
UserWarning: This ImageDataGenerator specifies `zca_whitening`, but it hasn't been fit on any training data. Fit it first by calling `.fit(numpy_data)
いったんfitさせれば変換もされるのだと思い試したところ画像が小さくないとダメで、そんでもって。結果もイマイチあってんだか、あってないんだかよくわからない。
そもそも無相関にするのは何の相関?RGB間の相関のように思えるが果たしてそうなのだろうか?
from keras.preprocessing.image import ImageDataGenerator
import cv2
import numpy as np
x = cv2.imread('lena.png')
x = x.reshape((1,) + x.shape)
datagen = ImageDataGenerator(
featurewise_center=True,
zca_whitening=True)
datagen.fit(x)
d = datagen.flow(x, batch_size=1).next()
# 0-255の画像化するための処理
ofs = np.max(d[0])
if np.abs(np.min(d[0])) > ofs:
ofs = np.abs(np.min(d[0]))
cv2.imwrite("lena_whitening.png", (d[0]+ofs)/(2*ofs)*255)
print("std: ", np.std(d[0]))
print("ave: ", np.mean(d[0]))
平均も標準偏差も標準化した時のようにわかりやすい数字にならない。
std: 0.0045105484
ave: 2.2312936e-10

画像が荒いのは128×128に縮小して処理したため。左が入力で右が出力。
知識として、白色化ってテクニックがあって、おそらく通常強い相関があるはずのRGBの相関をなくして、標準化する。ってことだと認識しておくことにします。
バッチノーマライゼーション
これも正規化・標準化の一種と考えてよさそうなので記載しておきます。
入力だけ正規化するのではなく、各層への入力に対してもそれぞれミニバッチ毎に正規化(標準化)すること。学習の効率が上がることが期待されるようです。
これはややこしい。ひとまずキーワードだけ置いといて、ググるとしましょう。

コメント