ゼロから作るDeepLearning③を読み切って初めて普段使っているpytorchの動きの意味が分かってきた気がします。今まで意味も分からず書いていた記述一つ一つの意味だったり意図が分かった気になってきました。
そして意図的にだと思いますが、記述スタイルもよく似ています。どうやらChainerともスタイルは似ているようです。そこで書籍のサンプルコードをpytorchで置き換えてみたらどうなるか試してみようと思います。
torch.tensor
これがDeZeroでいうところのVariableに当たります。Chainerは同じようにVariableだそうです。
backwardもdataもgradもあります。ただこいつはdataもtensorなので、dataの実態がnumpyだったDeZeroとはこの辺りは異なります。
またtensorはデフォルト宣言時には勾配非保持モードのようです。あと小数もfloat32がデフォルトのようです。
step9 関数をより便利に
まずはシンプルなコードを書き換えてみます。
# DeZero
x = Variable(np.array(0.5))
y = square(exp(square(x)))
y.backward()
print(x.grad)
これをpytorchに置き換えると
# torch
x = torch.tensor(0.5, requires_grad=True, dtype=torch.float64)
y = torch.exp(x**2) ** 2
y.backward()
print(x.grad)
Variableをtensorに置き換えているだけです。結果を完全一致させるために型も指定しています。結果 tensor(3.2974425414002559, dtype=torch.float64) と完全一致しました。
step24 複雑な関数の微分
やや複雑な関数の微分に関して。コードはDeZeroとtorchでほぼ同じです。元コードは
# DeZero
def sphere(x, y):
z = x ** 2 + y ** 2
return z
def matyas(x, y):
z = 0.26 * (x ** 2 + y ** 2) - 0.48 * x * y
return z
def goldstein(x, y):
z = (1 + (x + y + 1)**2 * (19 - 14*x + 3*x**2 - 14*y + 6*x*y + 3*y**2)) * \
(30 + (2*x - 3*y)**2 * (18 - 32*x + 12*x**2 + 48*y - 36*x*y + 27*y**2))
return z
x = Variable(np.array(1.0))
y = Variable(np.array(1.0))
z = goldstein(x, y) # sphere(x, y) / matyas(x, y)
z.backward()
print(x.grad, y.grad)
そしてこちらがtorch版です。演算子をオーバーロードしているのでほっとんど同じです。3つの関数は完全一致。変数の宣言のところだけ。
# torch
def sphere(x, y):
z = x ** 2 + y ** 2
return z
def matyas(x, y):
z = 0.26 * (x ** 2 + y ** 2) - 0.48 * x * y
return z
def goldstein(x, y):
z = (1 + (x + y + 1)**2 * (19 - 14*x + 3*x**2 - 14*y + 6*x*y + 3*y**2)) * \
(30 + (2*x - 3*y)**2 * (18 - 32*x + 12*x**2 + 48*y - 36*x*y + 27*y**2))
return z
x = torch.tensor(1., requires_grad=True) # 違いはここだけ
y = torch.tensor(1., requires_grad=True) # 違いはここだけ
z = goldstein(x,y) # matyas(x, y) # sphere(x, y)
z.backward()
print(x.grad, y.grad)
きれいに同じ値の微分が求まりました。
step28 関数の最適化
勾配降下法を試してみます。これもほっとんど同じ記述で同じ結果を得られました。
# DeZero
def rosenbrock(x0, x1):
y = 100 * (x1 - x0 ** 2) ** 2 + (x0 - 1) ** 2
return y
x0 = Variable(np.array(0.0))
x1 = Variable(np.array(2.0))
lr = 0.001 # 学習率
iters = 1000 # 繰り返す回数
for i in range(iters):
print(x0, x1)
y = rosenbrock(x0, x1)
x0.cleargrad()
x1.cleargrad()
y.backward()
x0.data -= lr * x0.grad
x1.data -= lr * x1.grad
tensorには.cleargrad()の関数がないので代わりに.grad=Noneを代入しています。違いは宣言含めて4か所だけ。
# torch
def rosenbrock(x0, x1):
y = 100 * (x1 - x0 ** 2) ** 2 + (x0 - 1) ** 2
return y
x0 = torch.tensor(0., requires_grad=True, dtype=torch.float64) # ここ
x1 = torch.tensor(2., requires_grad=True, dtype=torch.float64) # ここ
lr = 0.001 # 学習率
iters = 1000 # 繰り返す回数
for i in range(iters):
print(x0, x1)
y = rosenbrock(x0, x1)
x0.grad = None # ここ
x1.grad = None # ここ
y.backward()
x0.data -= lr * x0.grad
x1.data -= lr * x1.grad
ただNoneを直で代入するのは少し気が引けるので、勾配のクリアをちゃんとIF経由でやることにします。
for文の中だけ
# torchっぽく
for i in range(iters):
print(x0, x1)
y = rosenbrock(x0, x1)
# x0.grad = None # Dezero的
# x1.grad = None # Dezero的
y.backward()
x0 = x0 - lr * x0.grad # pytorch的 この計算でis_leafも失われる
x1 = x1 - lr * x1.grad # pytorch的
# x0.data -= lr * x0.grad # Dezero的 この計算ではis_leafは失われない
# x1.data -= lr * x1.grad # Dezero的
x0 = x0.detach().requires_grad_() # pytorch的
x1 = x1.detach().requires_grad_() # pytorch的
意味は同じです。ちなみにプロットも含めた最終的なtorchなコードは
# torch
import torch
from matplotlib import pyplot as plt
def rosenbrock(x0, x1):
y = 100 * (x1 - x0 ** 2) ** 2 + (x0 - 1) ** 2
return y
x0 = torch.tensor(0., requires_grad=True, dtype=torch.float64)
x1 = torch.tensor(2., requires_grad=True, dtype=torch.float64)
lr = 0.001 # 学習率
iters = 1000 # 繰り返す回数
plt.xlim((-2.0, 2.0))
plt.ylim((-1.0, 3.0))
plt.scatter(1.0, 1.0, marker='*', c='blue') # 最小値
for i in range(iters):
print(x0, x1)
plt.scatter(x0.detach(), x1.detach())
y = rosenbrock(x0, x1)
y.backward()
x0 = x0 - lr * x0.grad # pytorch的
x1 = x1 - lr * x1.grad # pytorch的
x0 = x0.detach().requires_grad_() # pytorch的
x1 = x1.detach().requires_grad_() # pytorch的
plt.show()
このプロット結果が
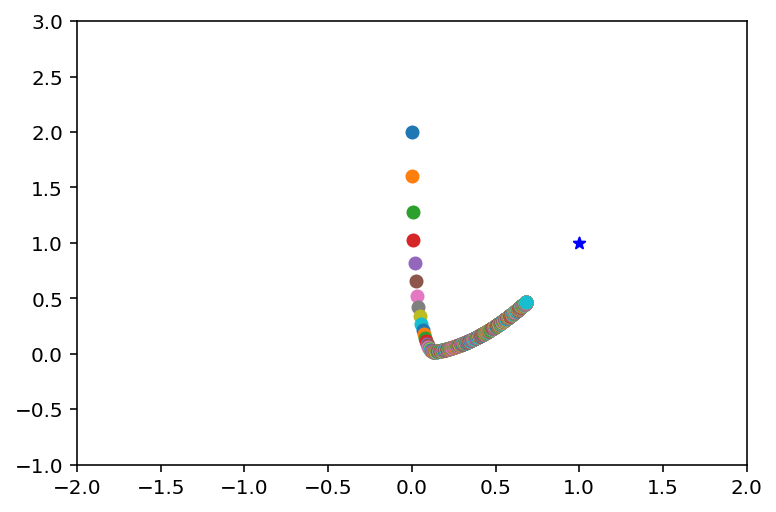
です。等高線を書くのはあきらめました。書籍と同じような軌跡を描いています。
step33 ニュートン法を使った最適化(自動計算)
2階微分のコードもpytorchで試してみます。勾配に対して再度backwardする例です。
# DeZero
def f(x):
y = x ** 4 - 2 * x ** 2
return y
x = Variable(np.array(2.0))
iters = 10
for i in range(iters):
print(i, x)
y = f(x)
x.cleargrad()
y.backward(create_graph=True)
gx = x.grad
x.cleargrad()
gx.backward()
gx2 = x.grad
x.data -= gx.data / gx2.data
これをtorchで真似ると
# torch
def f(x):
y = x ** 4 - 2 * x ** 2
return y
x = torch.tensor(2.0, requires_grad=True, dtype=torch.float64)
iters = 10
for i in range(iters):
print(i, x)
y = f(x)
x.grad = None # ここ①
y.backward(create_graph=True)
gx = x.grad
x.grad = None # ここ②
gx.backward()
gx2 = x.grad
x.data -= gx.data / gx2.data
cleargradがないがために入れた記述(ここ①と②)以外は同じ。ほぼ互換です。ただこれを実行するとワーニングが表示されます。
backward() を create_graph=True のオプション付きで使用すると、メモリリークの原因となる可能性があることを警告しています。パラメータ(重み)とその勾配の間に 循環参照が発生し、メモリリークする可能性があるそうです。この問題を回避するには、代わりに torch.autograd.grad() を使用することが推奨されています。使用後に.gradにNoneを入れろとのことで、今回は幸いにも②のところでそれを実施しているので、大丈夫のように見えます。
推奨のコードに書き換えてみます。
# torch
def f(x):
y = x ** 4 - 2 * x ** 2
return y
x = torch.tensor(2.0, requires_grad=True, dtype=torch.float64)
iters = 10
for i in range(iters):
print(i, x)
y = f(x)
grads = torch.autograd.grad(y, x, create_graph=True) # ここ
gx = grads[0] # 1階微分
grads[0].backward()
gx2 = x.grad # 2階微分
x = x - gx / gx2 #
x = x.detach().requires_grad_() #
これなら同じ結果でワーニングは出ません。
step34 sin関数の高階微分
sin/cosの行ったり来たりを試したコードです。これも書き換えてみます。
# DeZero
x = Variable(np.linspace(-7, 7, 200))
y = F.sin(x)
y.backward(create_graph=True)
logs = [y.data]
for i in range(3):
logs.append(x.grad.data)
gx = x.grad
x.cleargrad()
gx.backward(create_graph=True)
labels = ["y=sin(x)", "y'", "y''", "y'''"]
for i, v in enumerate(logs):
plt.plot(x.data, logs[i], label=labels[i])
plt.legend(loc='lower right')
plt.show()
これもpytorchで置き換えてみます。pytorchのbackwardはどうやらスカラーでしか動かないようです。そのため結果を加算(sum)してスカラーにしたうえで逆伝播させます。
# torch
x = torch.tensor(np.linspace(-7, 7, 200), requires_grad=True)
y = torch.sin(x)
z = y.sum() # ここ
z.backward(create_graph=True)
logs = [y.data]
for i in range(3):
logs.append(x.grad.data)
gx = x.grad.sum() # ここ
x.grad = None
gx.backward(create_graph=True)
labels = ["y=sin(x)", "y'", "y''", "y'''"]
for i, v in enumerate(logs):
plt.plot(x.data, logs[i], label=labels[i])
plt.legend(loc='lower right')
plt.show()
ここで示した箇所でsumをとっている以外はほとんど変えていません。ただ前述の通り非推奨なコードです。
この実行結果は
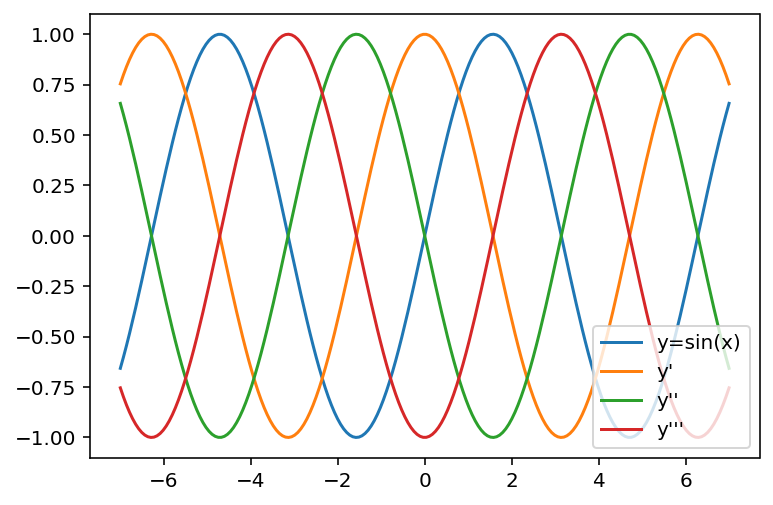
これなので、書籍記載の通りです。
step42 線形回帰
だんだんコードが込み入ってきました。がこれも簡単に書き換えができて、よりtorchで何が行われているか理解が深まってきます。グラフのプロットのためのコード記述は省きます。
# DeZero
# Generate toy dataset
np.random.seed(0)
x = np.random.rand(100, 1)
y = 5 + 2 * x + np.random.rand(100, 1)
x, y = Variable(x), Variable(y)
W = Variable(np.zeros((1, 1)))
b = Variable(np.zeros(1))
def predict(x):
y = F.matmul(x, W) + b
return y
def mean_squared_error(x0, x1):
diff = x0 - x1
return F.sum(diff ** 2) / len(diff)
lr = 0.1
iters = 100
for i in range(iters):
y_pred = predict(x)
loss = mean_squared_error(y, y_pred)
W.cleargrad()
b.cleargrad()
loss.backward()
# Update .data attribute (No need grads when updating params)
W.data -= lr * W.grad.data
b.data -= lr * b.grad.data
print(W, b, loss)
これに対してtorchで等価な動きをさせます。
# torch
# Generate toy dataset
np.random.seed(0)
x = np.random.rand(100, 1)
y = 5 + 2 * x + np.random.rand(100, 1)
x, y = torch.tensor(x, requires_grad=True), torch.tensor(y, requires_grad=True) # ここ
W = torch.tensor(np.zeros((1, 1)), requires_grad=True) # ここ
b = torch.tensor(np.zeros(1), requires_grad=True) # ここ
def predict(x):
y = torch.matmul(x, W) + b # ここ
return y
def mean_squared_error(x0, x1):
diff = x0 - x1
return torch.sum(diff ** 2) / len(diff) # ここ
lr = 0.1
iters = 100
for i in range(iters):
y_pred = predict(x)
loss = mean_squared_error(y, y_pred)
W.grad = None # ここ
b.grad = None # ここ
loss.backward()
# Update .data attribute (No need grads when updating params)
W.data -= lr * W.grad.data
b.data -= lr * b.grad.data
print(W, b, loss)
ここ。ってコメント入れたところだけです。ほぼ機械的に置き換えができてしまっています。これでプロットまでさせると
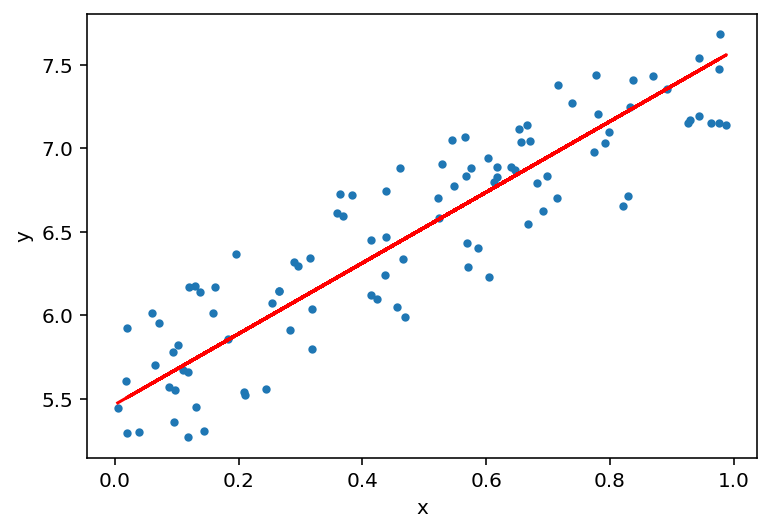
こんな感じ。書籍の通りのグラフがほぼ機械的な置き換えでtorchで書けてしまいました。
step48 多値分類
全結合のニューラルネットワークに関しても大変よく似た記述で行けます。プロット周りは省略します。
# DeZero
# Hyperparameters
max_epoch = 300
batch_size = 30
hidden_size = 10
lr = 1.0
x, t = dezero.datasets.get_spiral(train=True)
model = MLP((hidden_size, 3))
optimizer = optimizers.SGD(lr).setup(model)
data_size = len(x)
max_iter = math.ceil(data_size / batch_size)
for epoch in range(max_epoch):
# Shuffle index for data
index = np.random.permutation(data_size)
sum_loss = 0
for i in range(max_iter):
batch_index = index[i * batch_size:(i + 1) * batch_size]
batch_x = x[batch_index]
batch_t = t[batch_index]
y = model(batch_x)
loss = F.softmax_cross_entropy(y, batch_t)
model.cleargrads()
loss.backward()
optimizer.update()
sum_loss += float(loss.data) * len(batch_t)
# Print loss every epoch
avg_loss = sum_loss / data_size
print('epoch %d, loss %.2f' % (epoch + 1, avg_loss))
一方torchですが、MLPに相当するクラスはないので、自前で作る必要があります。今回TwoLayerNNとしてクラスを作成しました。
# torch
# Hyperparameters
max_epoch = 300
batch_size = 30
hidden_size = 10
lr = 1.0
x, t = get_spiral(train=True)
model = TwoLayerNN(hidden_size, 3) # ここ
optimizer = optim.SGD(model.parameters(), lr=lr) # ここ
data_size = len(x)
max_iter = math.ceil(data_size / batch_size)
for epoch in range(max_epoch):
model.train() # ここ
# Shuffle index for data
index = np.random.permutation(data_size)
sum_loss = 0
for i in range(max_iter):
batch_index = index[i * batch_size:(i + 1) * batch_size]
batch_x = torch.tensor(x[batch_index]) # ここ
batch_t = torch.tensor(t[batch_index]) # ここ
optimizer.zero_grad() # ここ
y = model(batch_x)
loss = F.cross_entropy(y, batch_t) # ここ
loss.backward()
optimizer.step() # ここ
sum_loss += float(loss.data) * len(batch_t)
# Print loss every epoch
avg_loss = sum_loss / data_size
print('epoch %d, loss %.2f' % (epoch + 1, avg_loss))
get_spiralはDeZeroのコードを引っ張ってきました。いろいろ調べてみたところoptimizerの書式はChainerを真似ているようです。またcross_entropyという関数内部でsoftmaxも実行されているようです。
ちなみに上述のTowLayerNNの実装は以下。データ入力時に動的に入力チャネル数を決めるような仕組みが作れなかったので入力2chは固定です。
# 2層の全結合ニューラルネットワーク
class TwoLayerNN(nn.Module):
def __init__(self, hidden_size, out_size):
super(TwoLayerNN, self).__init__()
self.fc1 = nn.Linear(2, hidden_size) # 入力2 -> 隠れ層10
self.fc2 = nn.Linear(hidden_size, out_size) # 隠れ層10 -> 出力3
def forward(self, x):
x = F.sigmoid(self.fc1(x))
x = self.fc2(x)
return x
こんな感じ。畳み込みはどうしてもfloat32になってしまいましたが結果に大きな差は出ないかと。
Lossの推移は
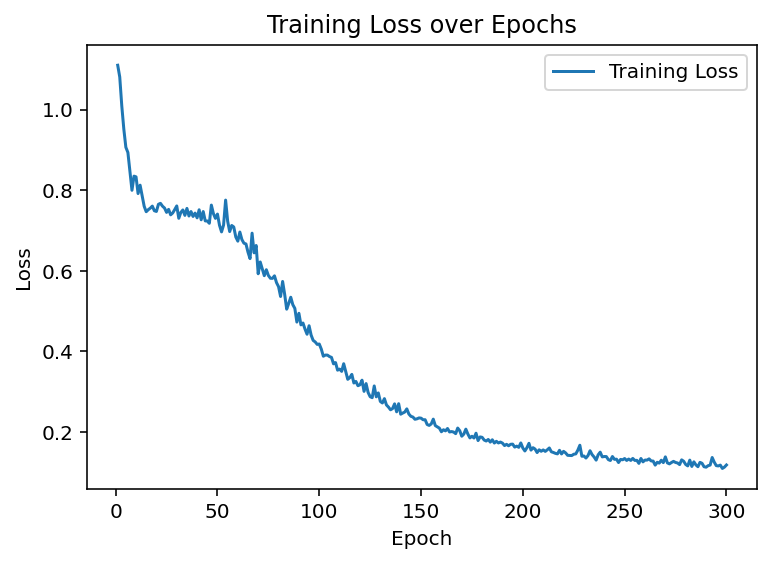
分離の決定境界は
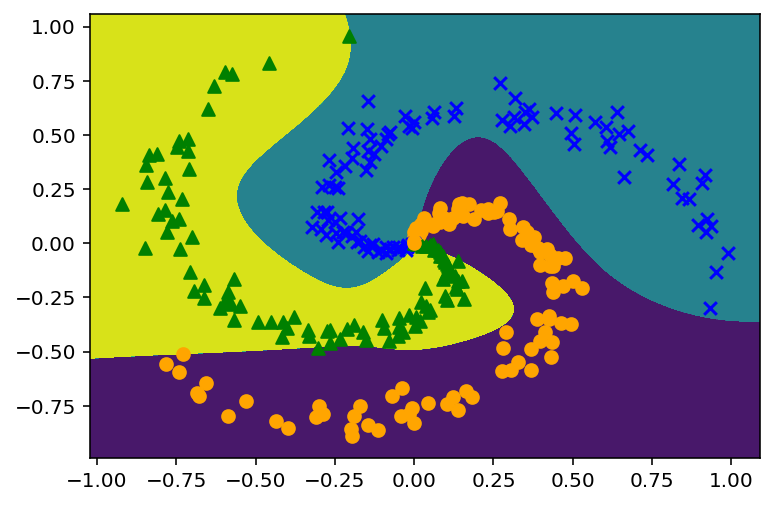
おおむね近い結果が得られています。
まとめ
数パターンDeZeroのコードをPyTorchへ置き換えてみましたが、大変よく似た記述で実現できました。DeZero本当によくできています。この書籍はフレームワークの学習教材としてはとても良いです。フレームワークの中で何が行われているか、改めてよくわかりました。
コメント